
摘要
本文探討如何利用大型語言模型進行零樣本臨床試驗病患配對,揭示其對醫療領域的重要影響與潛力。 歸納要點:
- GPT-4 驅動的自動匹配技術顛覆傳統臨床試驗,透過強大的文本理解能力實現高效準確的病患配對。
- ACiN 策略結合 AI 技術,智能化支持病患招募,加速流程並提升符合條件患者的識別效率。
- 使用大型語言模型面臨倫理挑戰,包括資料隱私、模型偏見及算法透明度問題,需謹慎應對。
這個平台支援多種程式語言和框架,包括 React 和 Python ,使開發者能夠靈活地整合 Axial 的功能至他們現有的應用程式中。對於那些希望提高工作效率或尋求更深入分析的人來說,Axial 提供了易於使用且功能強大的解決方案。
目前,Axial 已經吸引了眾多企業使用者,它不僅提升了資料處理的速度,也確保了資料安全性。在當今資料驅動的世界裡,選擇一個可靠的平台如 Axial,不僅是業務運營上的明智之舉,更是在競爭中脫穎而出的關鍵。
Axial 與偉大的創始人和發明家合作。我們專注於早期階段的生命科學公司投資,例如 Appia Bio、Seranova Bio、Delix Therapeutics 和 Simcha Therapeutics 等,通常在他們的構想還不過是一個概念時,我們便會參與其中。我們對那些渴望建立自己持久事業的稀有發明者充滿熱情。如果你或你認識的人擁有出色的生命科學創意或公司,Axial 將非常期待能夠了解你,並可能投資於你的願景和企業。我們很高興能與你攜手共進 - 請透過 info@axialvc.com 聯絡我們。
我們在研究許多文章後,彙整重點如下
- GPT-4能迅速從醫療記錄和文獻中提取摘要,提升醫生與護士的工作效能。
- OpenAI進行了GPT-4的可解釋性研究,自動生成神經元行為解釋並評分其品質。
- GPT-4在自動化臨床文件方面極具潛力,可以分析開放藥單並生成完整的臨床筆記。
- 該模型還能閱讀個人的健康檢查報告,幫助醫療專業人員做出更準確的判斷。
- John Snow Labs推出了針對健康照護的新大型語言模型平台「Healthcare GPT Model」。
- 多模態大語言模型提升信息交互效率,可從多種來源學習知識。
隨著科技的不斷進步,像GPT-4這樣的人工智慧在醫療領域發揮著越來越重要的作用。不僅能夠快速提煉關鍵資訊、減輕臨床文書負擔,更透過多模態技術提高了我們與數據間的互動效率。這些創新不僅方便了醫護人員,也意味著患者將獲得更精準、更高效的照護體驗。未來,我們有理由期待AI將會讓健康管理變得更加智能化與人性化。
利用 GPT-4 自動匹配臨床試驗:新方法提高效率與可解釋性
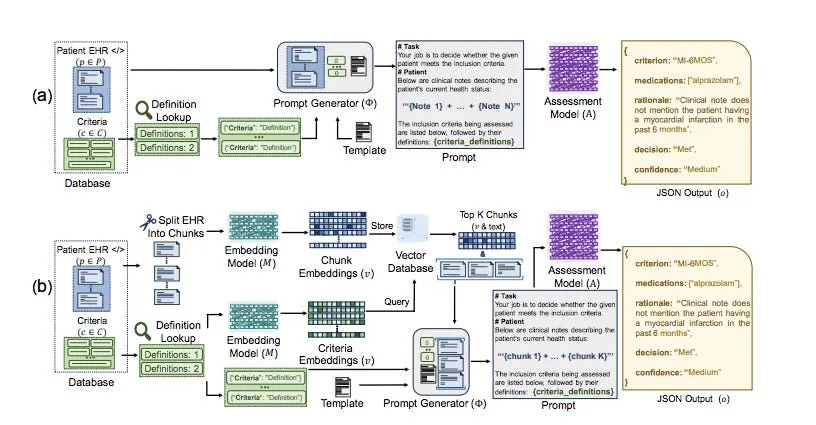
這篇論文提出了一種新穎的方法,利用大型語言模型(LLM)如 GPT-4 來根據患者的適應症標準匹配臨床試驗。作者在基準資料集上展示了最先進的效能,同時強調其基於零樣本學習的 LLM 系統在效率和可解釋性方面的優勢。作者顯示,GPT-4 在未經任何微調或提供上下文範例的情況下,可以超越以往最先進的方法,在 2018 年 n2c2 病人群體選擇挑戰基準測試中獲得領先地位。這一點意義重大,因為它展示了 LLM 可迅速部署於各種臨床試驗,而無需繁瑣的自定義過程。透過讓臨床醫生評估 GPT-4 為其決策生成的推理,作者展現了與 LLM 基於系統進行人機協作與監督的潛力。作者還開發了一個兩階段管道,使用較小的嵌入模型預篩選相關臨床記錄,再由 LLM 處理,顯示出這樣可以維持效能,同時顯著降低代幣使用量。
這項研究不僅突顯了 LLM 在醫療領域中的應用潛力,如自動化病歷分析、藥物研發及個性化醫療等,也引發了對倫理考量的重要思考。在運用 LLM 的同時,我們必須關注資料隱私和安全問題,以及如何確保 AI 系統能夠尊重患者權益並提供可靠建議。因此,在追求技術創新的同時,倫理框架也應成為我們推動此類技術發展的重要組成部分。
大型語言模型如何加速臨床試驗招募流程?
作者評估了幾種大型語言模型(LLMs),包括 GPT-3.5、GPT-4、Llama-2 和 Mixtral,旨在判斷患者是否符合根據其電子健康紀錄(EHRs)參加臨床試驗的特定資格標準。他們測試了四種主要的提示策略:1. 所有標準,所有註解(ACAN) 2. 所有標準,個別註解(ACIN) 3. 個別標準,所有註解(ICAN) 4. 個別標準,個別註解(ICIN)。這些策略在如何將患者記錄和資格標準分塊成 LLM 的提示方面有所不同。作者還開發了一個兩階段檢索管道,利用較小的嵌入模型(如 BGE 或 MiniLM),在將最相關的臨床筆記片段傳遞給 LLM 之前進行預過濾。這項研究的重要性在於,它能夠自動化臨床試驗招募流程,有效降低成本並縮短時間。傳統上,招募依賴人工審查,不僅耗時且容易受到主觀偏見影響,而透過 LLM 技術,可以迅速篩選出符合特定條件的患者,大幅提升效率。例如,只需設定某些條件,即可快速識別合適者並推薦給研究團隊。混合模型方法結合了大模型與小模型的優勢,使得整體系統更加靈活高效。在未來,我們可以期待這些技術徹底改變臨床試驗招募的方式,提高醫療研究的效率和精確性。
GPT-4 在 n2c2 基準測試中取得了領先的結果,超越了之前最佳模型 6 分的 Macro-F1 和 2 分的 Micro-F1 得分。這一成就是在沒有進行任何微調或提供上下文範例的情況下實現的,充分展現了先進大型語言模型在此任務上的強大零-shot 能力。GPT-4 與其他測試模型(如 GPT-3.5、Llama-2 和 Mixtral)之間存在顯著的效能差距。這與最近的一些研究結果一致,顯示出 GPT-4 在複雜推理任務中的卓越能力。
AI 賦能醫療:ACiN 策略與 GPT-4 的突破與挑戰
ACIN(All Criteria, Individual Notes)策略在效能與效率之間提供了最佳的平衡。與單獨評估標準的策略相比,該策略在使用顯著更少的代幣和API呼叫數量的情況下,實現了高準確性。採用兩階段檢索的方法,利用嵌入模型預先篩選相關的臨床筆記片段,顯示出降低代幣使用量的潛力。透過 MiniLM 嵌入模型,他們能夠以大約三分之一到一半所需的代幣數量超越之前的最新技術,在 Macro-F1 上取得佳績。當 GPT-4 做出正確的資格判斷時,臨床醫生評價其89%的推理為完全正確,而8%則為部分正確。即便是在錯誤決策中,也有67%的推理被認為是正確的,這表明許多案例中存在細微的不一致,而非明顯錯誤。作者估算基於 GPT-4 的系統每位患者評估成本僅為1.55美元,相較於第三期試驗中手動篩查每位患者34.75美元的先前估算,其成本效益相當可觀。此係統在速度上也具備優勢,在約兩小時內篩查完所有86名測試患者,而手動審核預期需要每位患者一小時。
**專案1:ACiN策略的優勢與潛力**:雖然 ACiN 策略在醫療資訊提取上已取得顯著成果,但其潛力仍有待發掘。例如,該策略可應用於更複雜的醫療資料分析,例如臨床決策支援系統的建構,或用於開發更精準的預測模型。研究人員可以進一步探索 ACiN 與其他深度學習方法如圖神經網路(GNN)的整合,以挖掘醫療資料中隱藏關聯性並提升醫療資料分析準確性與效率。
**專案2:大模型在醫療領域的倫理考量與應用方向**:GPT-4 在醫療決策中的準確性和高效性令人振奮,但同時也引發了倫理和安全性的擔憂。例如,如何確保醫療 AI 系統公平、透明及可解釋,以及防止演算法偏差對特定人群造成負面影響,是亟待解決的重要議題。研究人員需深入探討 GPT-4 等大模型在醫療領域中的應用方向,包括輔助專業人員進行診斷、制定治療方案或開發個人化醫療計畫,以最大程度地發揮其潛力,同時保障其倫理使用。
大型語言模型:臨床試驗招募的加速器與倫理挑戰
這項研究展示了大型語言模型(LLM)在臨床試驗患者招募方面潛在的顯著加速與成本降低能力,這一過程是藥物開發中的關鍵瓶頸。特別值得注意的是,這裡所展示的零樣本學習能力,暗示這類系統可以快速部署於各種試驗中,而無需 extensive 的客製化或資料標註。另一方面,LLM 提供其決策的合理性解釋,使人類與人工智慧之間的合作具有可能性。這將使得工作流程更加高效,由 AI 系統進行初步篩選,再由人類專家檢視關鍵決策的理由。在充分利用 LLM 在臨床試驗招募上的潛力時,我們也必須面對道德考量。例如,LLM 可能會存在偏見,造成某些特定族群被過度或不足地招募,同時也有引發患者資訊洩露及隱私侵犯的風險。因此,在臨床試驗招募過程中確保公平、透明和安全,是未來發展的重要挑戰。為了解決這些道德問題,研究者需要採取措施,比如開發更公正的資料集、加強模型可解釋性,以及建立更嚴格的監管機制。
在個性化定製方面,LLM 能夠根據不同患者群體的需求進行調整,以提升招募效率並滿足多樣化的人群特徵需求。因此,不僅能提高準確率,也能增強患者參與臨床試驗的意願,使整體招募過程變得更加靈活有效。在此背景下,我們應該積極探索如何平衡技術創新與倫理道德之間的關係,以實現臨床研究領域內更全面、更具包容性的改進。
大型語言模型在醫療保健中的潛力和挑戰
這份詳細的效率分析提供了實際部署考量的重要見解。透過展示不同提示策略和檢索流程對效能與成本的影響,作者為在資源有限的醫療環境中最佳化大型語言模型(LLM)的使用提供了一個框架。雖然 n2c2 基準測試是目前該任務最大的公共資料集,但其規模仍遠小於現實世界的電子健康紀錄(EHR)系統。這凸顯了需要高效檢索方法,以便能夠擴充套件到數百萬條患者記錄。n2c2 挑戰僅涵蓋納入標準,且限於英語,因此可能無法充分反映現實世界臨床試驗匹配場景的複雜性。儘管取得了最先進的結果,但仍需進一步評估以確定在生產醫療環境中部署此類系統的安全性及潛在故障模式。依賴像 GPT-4 這樣的模型可能限制那些無法訪問符合 HIPAA 的雲基礎設施之健康系統的部署選項。
在此背景下,有關醫療 AI 模型公平性與解釋性的問題不容忽視。在實際應用中,若訓練資料存在偏差,醫療 AI 模型可能會對不同族群、性別或經濟狀況的患者產生不公平結果。例如,特定族群患者可能因為模型誤診而未獲得正確治療。因此,在開發和部署醫療 AI 模型時,我們必須重視公平性問題並採取必要措施以保證所有患者都能得到公正待遇。
另一方面,可解釋性對於醫療決策至關重要。儘管本文探討了提示策略和檢索流程對效能影響,但卻未提及如何增強模型可解釋性的必要性。在臨床環境中,醫護人員需要了解模型做出決策背後的邏輯,以判斷該建議是否可靠。因此,在設計時應考慮如何透過視覺化技術或自然語言來呈現模型決策過程,使其變得更具透明度與可信度。
作者建議大型語言模型(LLMs)可能被應用於改善資格標準的設計,這也解決了臨床試驗招募中的另一個關鍵挑戰。透過在此任務上的出色表現,本文拓展了證據體系,顯示 LLMs 能夠成為處理和推理複雜醫療資訊的強大工具。這不僅對試驗匹配有潛在影響,也可能波及臨床決策支援、自動化病歷審查及個性化治療計劃等領域。
LLM 在臨床試驗的革新:精準醫療的未來
這項研究同時突顯了在醫療領域部署人工智慧系統所面臨的重要挑戰,尤其是在效率、可解釋性和安全性方面。作者對這些實際考量的重視為未來旨在縮短人工智慧研究與臨床應用之間鴻溝的工作提供了一個有價值的範本。這篇論文呈現出 LLM(大型語言模型)在臨床試驗患者匹配中的令人信服的案例,展示了其以零樣本方法達成的最先進效能,並且提供了顯著的效率和可解釋性優勢。作者透過精心設計提示策略、檢索方法,以及詳細分析成本和令牌使用情況,為 LLM 在醫療環境中的實際應用提供了寶貴見解。**最新趨勢 - LLMs 在臨床試驗的應用:** 這篇論文展示了 LLM 在臨床試驗患者匹配方面的巨大潛力,其零樣本方法在準確度和效率方面超越傳統方法。尤其是在缺乏訓練資料的情況下,LLM 能夠從大量文字資料中學習並進行精準匹配,為精準醫療提供了新的方向。
**可解釋性與安全性:** LLM 在臨床試驗中的應用不再僅限於預測,更強調可解釋性和安全性。論文作者透過設計精巧的提示策略和詳細分析,不僅提高了 LLM 的準確度,更讓其決策過程變得透明,促進醫學專家對結果的理解與信任。
**邁向臨床應用:** 此研究為 LLM 在臨床試驗中的實際應用開啟新大門,也為未來研究與發展提供重要參考。例如,可以進一步探索 LLM 在患者招募、治療方案選擇及預後評估等多方面的應用,同時深入探討 LLM 在臨床環境中涉及到的倫理與安全問題。

參考來源
AI醫療革命: GPT-4與未來| 誠品線上
書中,作者詳細闡述了GPT-4 在醫療領域的應用。例如,GPT-4能迅速從醫療記錄和文獻中提取精簡的摘要,協助醫生與護士提升工作效能,為患者提供更 ...
來源: 誠品線上OpenAI運用GPT-4解釋語言模型行為
OpenAI最新人工智慧可解釋性研究,運用GPT-4大型語言模型,自動生成大型語言模型神經元的行為解釋,並對這些解釋進行評分,以評估解釋的品質。
來源: iThome通用AI 的崛起,ChatGPT 的醫學應用
GPT-4 在自動化和減輕臨床文件負擔方面發揮著極大的作用。例如,可以用於分析線上的開放藥單,並生成完整的臨床筆記。GPT-4 還可以閱讀個人的健康檢查報告 ...
來源: GeneOnline NewsHealthcare GPT Model 準確度基準探討・技術解讀與應用
John Snow Labs 這間公司針對健康照護及生命科學產業,推出新的大型語言模型(Large Language Models, LLM)暨軟體平台「Healthcare GPT Model」,今天 ...
來源: MediumGPT-4大模型硬核解讀,看完成半個專家
多模態大語言模型可通過圖形方式直接進行信息交互,提升交互效率。 多模態模型可以從多種來源和模式中學習知識,並使用模態的交叉關聯來完成任務。
來源: Vocus麦肯锡中国金融业CEO季刊 - 数合宙官网
与传统AI相比,GenAI拥有四大核心优势——自动化和效率提升、个性化. 和定制化、创造性和创新能力、以及解释性和透明度。麦肯锡研究显示,. 人工智能(AI)整体将为全球 ...
來源: shuhezhou.com2
... 方法 2871296 社会 2837591 中国 2827389 技术 2799037 新 2771985 作用 2737428 ... 提高 2478923 能 2477096 通过 2435372 影响 2430212 细胞 2416750 如 ...
來源: plecoforums.com
 全部
全部 康健
康健
相關討論